정규식 테스터
정규식 하나 짜놓고 \d{4}-\d{2}-\d{2} 이게 진짜 내가 원하는 날짜만 잡을지, 아니면 엉뚱한 숫자까지 물어올지 코드에 넣기 전엔 확신이 안 서죠. 로그 파싱용으로 급하게 만든 패턴이 프로덕션에서 절반을 놓치는 걸 뒤늦게 발견하는 게 제일 뼈아픕니다. 정규식 테스터는 패턴과 대상 텍스트를 붙여넣으면 실제로 뭐가 매치되는지 그 자리에서 색으로 칠해 보여 주는 도구입니다.
저도 정규식을 자바스크립트 콘솔이나 코드에 임시로 박아 console.log로 확인하곤 했는데, 여러 줄 텍스트에서 뭐가 잡히고 뭐가 빠졌는지 눈으로 훑기가 어려웠습니다. 매치된 부분만 하이라이트로 딱 보이면 되겠다 싶어서, 입력하는 즉시 결과가 칠해지는 걸 만들었습니다.
사용 방법
-
위쪽 패턴 입력창에 정규식을 넣습니다. 양옆의
/는 구분자 표시라 그 사이 알맹이만 쓰면 됩니다. 오른쪽 샘플 버튼을 누르면 날짜 패턴 예시가 채워지니 감을 잡고 시작해도 됩니다.
-
패턴 아래 플래그 버튼으로 동작 방식을 켭니다.
g(모든 매치),i(대소문자 무시),m(여러 줄에서^·$를 줄 단위로),s(.이 줄바꿈도 포함),u(유니코드)까지 다섯 개를 지원합니다. 기본은g가 켜져 있습니다.
-
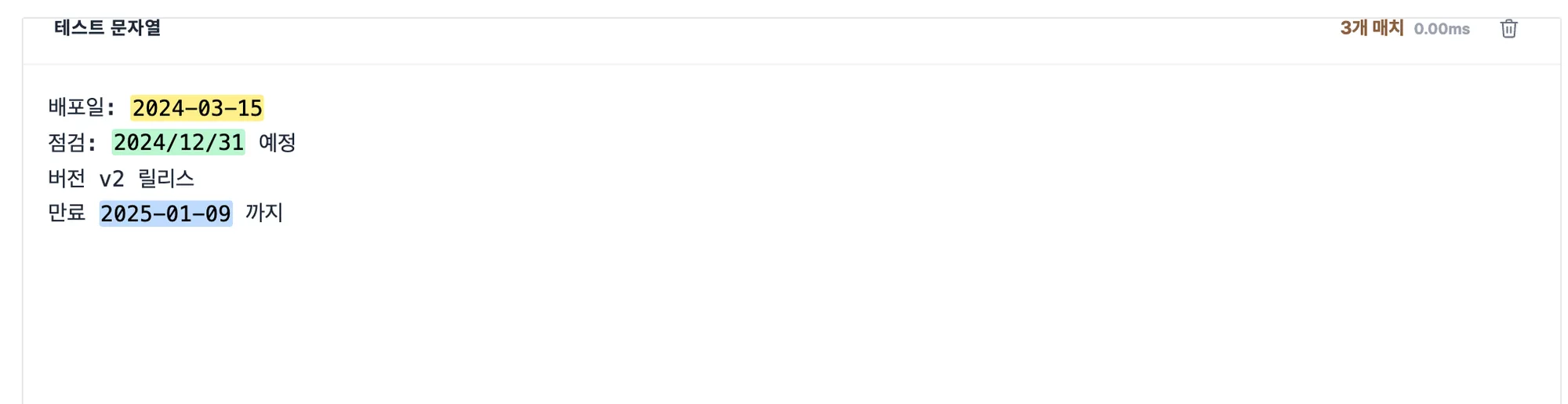
아래 테스트 문자열 칸에 대상 텍스트를 붙여넣으면 매치된 부분이 바로 색으로 칠해집니다. 여러 매치는 노랑·초록·파랑으로 번갈아 구분되고, 우측 상단에 총 몇 개가 잡혔는지 개수가 뜹니다. 잘못된 패턴을 넣으면 빨간 오류 메시지로 어디가 틀렸는지 알려 줍니다.
정규식 기본 문법
메타문자 몇 개만 손에 익으면 대부분의 패턴을 읽고 쓸 수 있습니다.
.: 줄바꿈을 뺀 아무 문자 하나.a.c는abc,a9c모두 매치.*/+: 앞 문자의 반복.*는 0개 이상,+는 1개 이상.ab+는ab,abbbb를 잡지만a하나는 안 잡습니다.?: 앞 문자가 있어도 되고 없어도 됨.colou?r는color와colour를 둘 다 잡습니다.\d: 숫자 하나(0~9).\w는 영문자·숫자·밑줄.\s는 공백류.[]: 문자 후보 묶음.[aeiou]는 모음 하나,[a-z]는 소문자 하나,[^0-9]는 숫자가 아닌 문자 하나.(): 그룹으로 묶기.(ab)+는abab처럼 덩어리째 반복을 봅니다. 괄호로 묶은 부분은 캡처 그룹으로도 잡힙니다.^/$: 문자열의 시작과 끝을 가리키는 앵커.^\d는 첫 글자가 숫자인지,.png$는.png로 끝나는지 검사합니다.m플래그를 켜면 이 앵커가 줄마다 적용됩니다.
{2,}처럼 중괄호로 반복 횟수를 직접 지정할 수도 있습니다. \d{4}는 숫자 정확히 4개, \d{2,4}는 2~4개입니다.
외워두면 두고두고 쓰는 패턴들
밑에 "자주 쓰는 패턴" 칩을 누르면 아래 몇 가지가 바로 입력창에 들어갑니다. 완벽한 검증용이라기보다 로그나 문서에서 해당 형태를 훑어 찾는 용도로 쓰기 좋습니다.
- 이메일:
[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}.아이디@도메인.tld꼴의 주소를 잡습니다. - URL:
https?://[^\s]+.http또는https로 시작해 공백 전까지 이어지는 링크를 통째로 잡습니다. - 한국 휴대폰:
01[016789]-?\d{3,4}-?\d{4}.010류로 시작하고 하이픈이 있든 없든 잡습니다. - 날짜:
\d{4}[-/]\d{2}[-/]\d{2}.2024-03-15나2024/12/31처럼 구분자가-든/든 잡습니다.
여기서 놓치기 쉬운 함정이 하나 있습니다. . 같은 특수문자를 진짜 마침표로 쓰고 싶다면 \.처럼 백슬래시로 이스케이프해야 한다는 점입니다. 이메일 패턴에서 도메인 앞 점을 \.로 쓴 것도 그 이유고요. 이걸 빼먹으면 .이 "아무 문자"로 해석돼서 의도보다 훨씬 넓게 잡힙니다. 패턴이 이상하게 많이 매치될 땐 이스케이프를 안 한 특수문자부터 의심해 보세요.