CSV 편집기
공공데이터포털에서 API를 CSV로 받아 보면 열이 수십 개씩 딸려 옵니다. 정작 쓰려는 건 이름, 주소, 좌표 서너 개뿐인데 관리번호, 갱신일자, 데이터기준일자 같은 열이 나머지를 다 채우고 있죠. CSV 편집기는 이렇게 넘쳐나는 열 중 필요 없는 걸 클릭 한 번으로 빼고, 남은 데이터를 JSON이나 YAML, XLSX로 바로 내보내는 도구입니다.
받은 CSV를 그대로 다음 단계에 넘기기 전에 매번 열부터 쳐내야 하는 게 번거로웠습니다. 스크립트를 새로 짜자니 열 하나 지우려고 그러기도 뭐하고, 엑셀로 열자니 한국 공공데이터는 인코딩이 엇나가 글자가 다 깨져 나왔거든요. 그래서 붙여넣거나 파일을 열면 열 목록이 바로 뜨고, 눈으로 보면서 지우고 포맷만 고르면 되도록 만들었습니다.
사용 방법
-
왼쪽 INPUT 패널에 CSV를 붙여넣거나 파일을 불러옵니다. 파일을 열면 인코딩을 자동으로 감지하고, 오른쪽 FIELDS 패널에 열 목록이 나타납니다. 뭘 넣을지 막막하면 샘플 버튼으로 시작해도 됩니다.
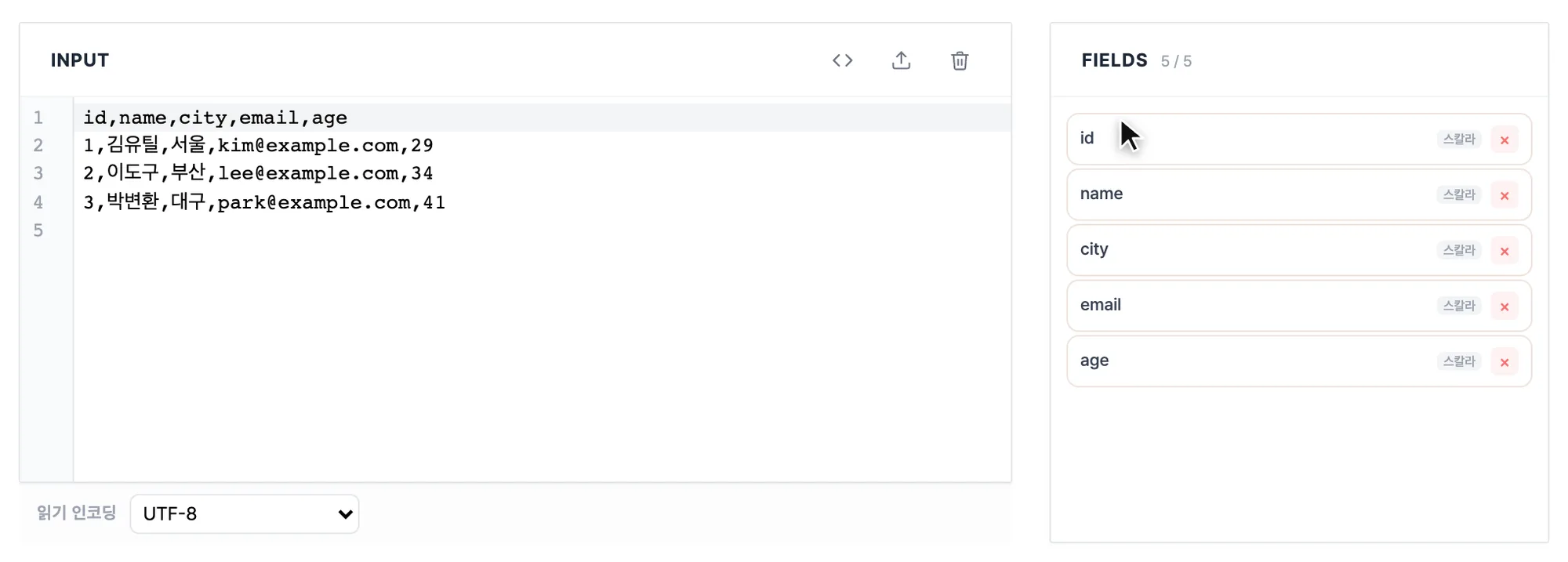
-
FIELDS 목록에서 필요 없는 열의 × 버튼을 눌러 제거합니다. 지운 열은 취소선으로 남으니 실수로 빼도 ↩ 버튼이나 상단 전체 복구로 되돌릴 수 있습니다. 열 이름이 마음에 안 들면 더블클릭해서 바꿀 수도 있고요.
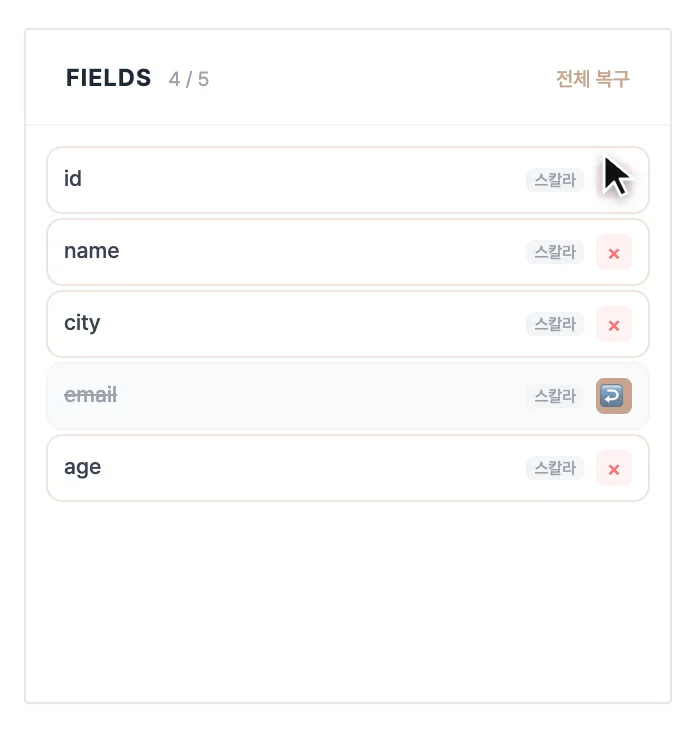
-
OUTPUT 패널 위에서 JSON, YAML, CSV, XLSX 중 원하는 포맷을 고릅니다. 남긴 열만으로 결과가 즉시 만들어지고, 복사 버튼이나 다운로드 버튼으로 가져갑니다.
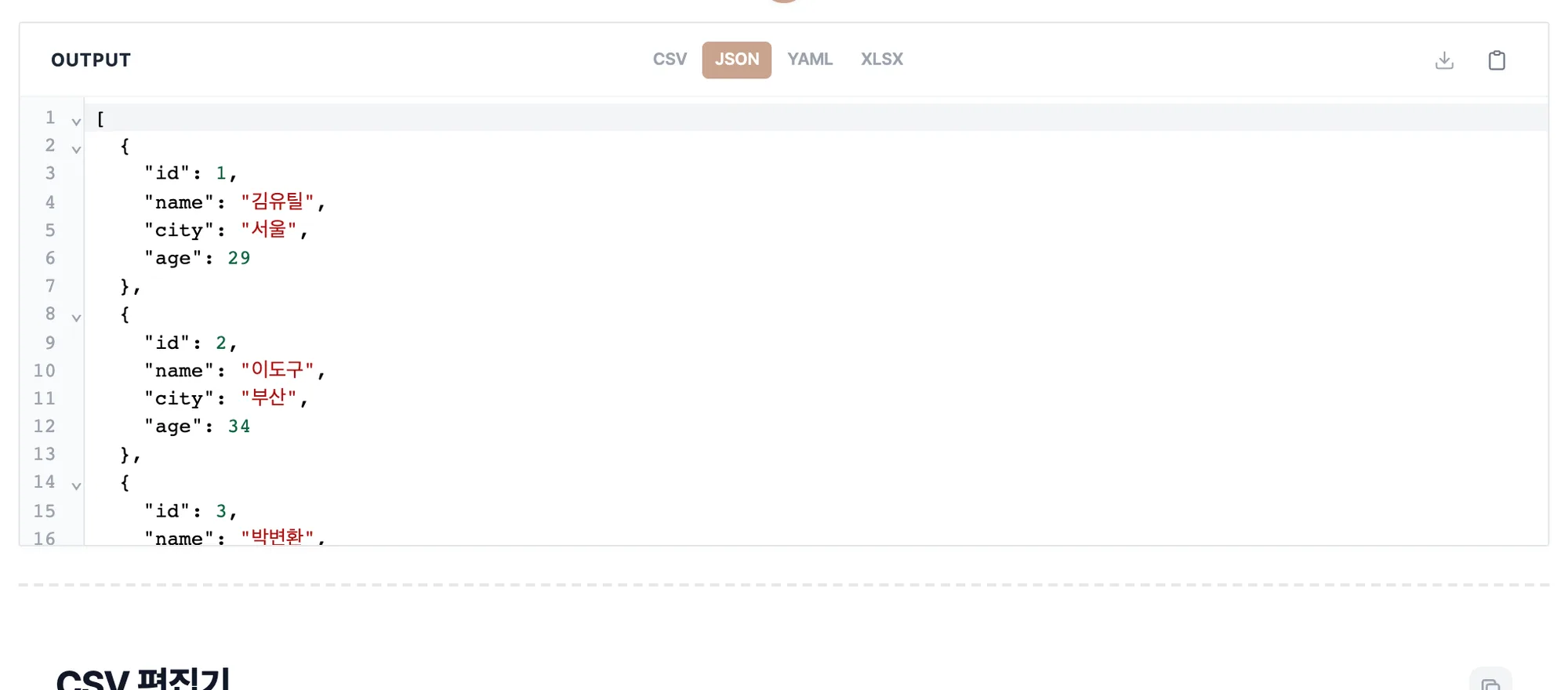
CSV에서 특정 열만 쉽게 지우는 방법
코드로 열을 빼는 방법은 이미 여러 가지가 있습니다. pandas면 df.drop(columns=['관리번호', '데이터기준일자'])로 한 줄이고, 표준 라이브러리만 쓴다면 csv.reader로 읽으면서 남길 열 인덱스만 골라 [row[i] for i in keep]로 재구성하면 됩니다. 열이 고정돼 있고 같은 작업을 반복한다면 이쪽이 낫습니다.
문제는 열이 뭐가 있는지부터 확인해야 하는 일회성 정리입니다. 헤더를 눈으로 훑고, 지울 이름을 리스트에 적고, 오타 나면 KeyError가 나서 다시 고치고. 이 도구는 그 과정을 FIELDS 목록에서 눈으로 보며 **×**로 처리하는 것으로 줄입니다. 남길지 뺄지 판단하면서 바로 클릭하니 헤더 이름을 따로 옮겨 적을 일이 없습니다.
한 가지 더, 한국 공공데이터를 다룰 때 가장 자주 걸리는 함정은 인코딩입니다. 상당수 CSV가 UTF-8이 아니라 EUC-KR(또는 CP949)로 내려오는데, 이걸 UTF-8로 읽으면 한글이 전부 깨져 나옵니다. pandas에서 UnicodeDecodeError를 만나 encoding='euc-kr'을 붙여 본 적이 있다면 그 상황입니다. 이 도구는 파일을 열 때 인코딩을 감지해 맞게 디코딩하고, 그래도 어긋나면 INPUT 아래 읽기 인코딩 드롭다운에서 EUC-KR로 다시 열 수 있습니다. 그렇게 제대로 읽은 데이터를 내보내면 결과는 UTF-8로 통일되니, 다음 단계에서 인코딩 때문에 다시 씨름할 일이 없습니다.