텍스트 비교기
콘솔에 찍힌 API 키를 대시보드 입력창에 손으로 옮겨 적었는데, 저장 버튼을 누르면 인증 실패가 납니다. 40자 넘는 무작위 문자열에서 l과 1, O와 0이 한 글자 어긋난 건 아무리 째려봐도 눈으로는 안 잡히죠. 텍스트 비교기는 원본과 옮겨 적은 값을 나란히 놓고, 정확히 어느 글자가 다른지 색으로 짚어 주는 도구입니다.
이런 값을 확인하겠다고 챗봇에 붙여넣기는 영 찜찜합니다. 시크릿 키나 토큰이 외부 서버로 올라가는 순간 그건 이미 유출이니까요. 그래서 이 비교기는 입력한 텍스트를 어디로도 보내지 않습니다. 두 값의 대조는 전부 브라우저 안에서 끝나고, 페이지를 닫으면 아무것도 남지 않습니다.
사용 방법
-
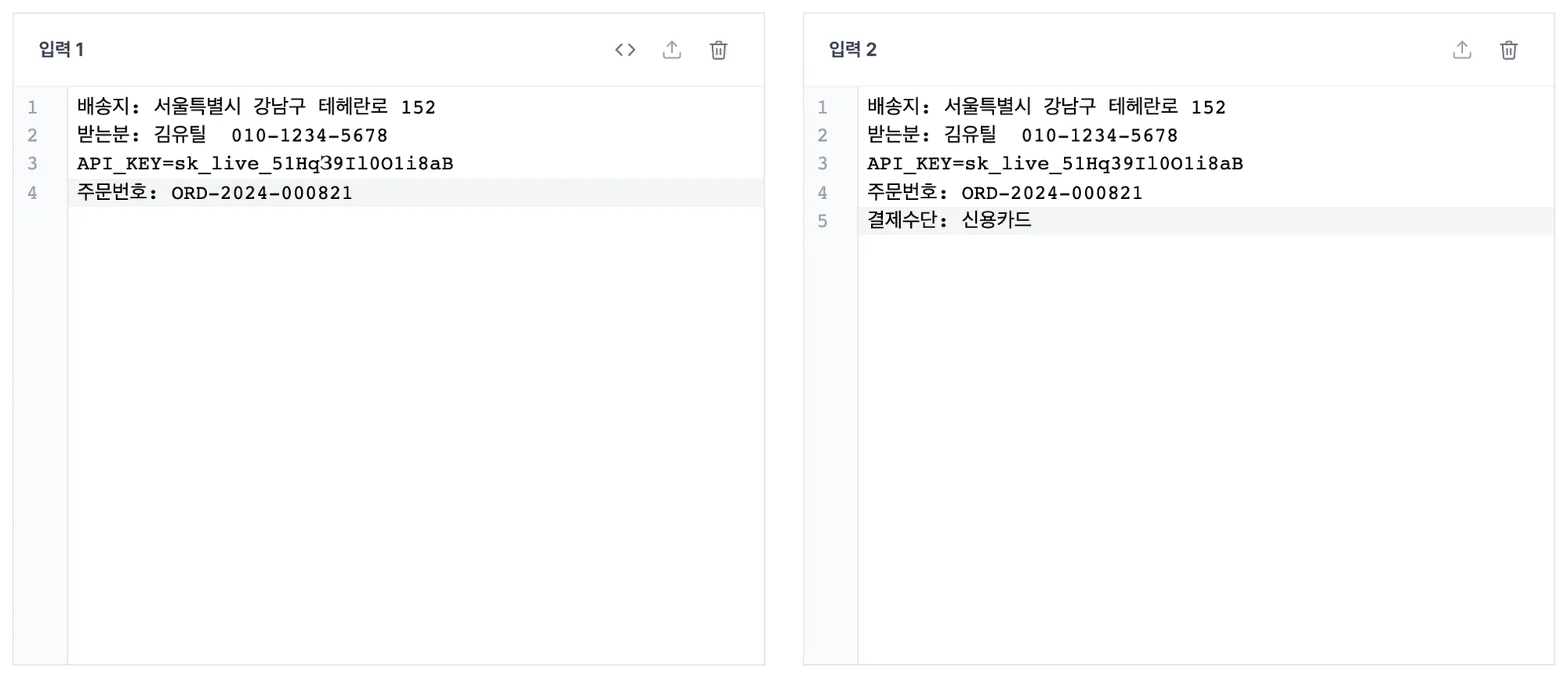
왼쪽 입력 1에 원본을, 오른쪽 입력 2에 옮겨 적은 값을 붙여넣습니다. 파일이라면 패널로 드래그하거나 업로드 아이콘으로 불러와도 됩니다.
-
아래 결과창에 두 텍스트가 줄 단위로 나란히 뜨고, 다른 줄은 색으로 표시됩니다. 다른 데만 보고 싶으면 다른 부분만 토글을 누르세요.

-
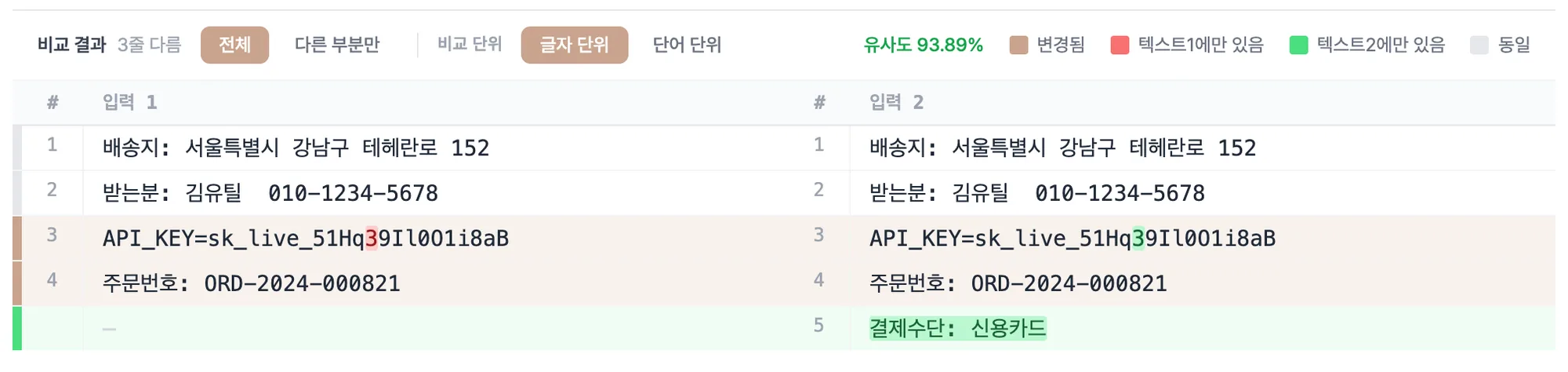
비교 단위를 글자 단위로 바꾸면, 바뀐 줄 안에서 정확히 어느 한 글자가 다른지까지 짚어 줍니다. 우측 유사도 퍼센트로 두 값이 얼마나 일치하는지도 한눈에 보입니다.
글자 단위와 단어 단위, 언제 뭘 쓰나
이 비교기는 먼저 두 텍스트를 줄 단위로 맞춘 뒤, 바뀐 줄 안에서 다시 글자 단위나 단어 단위로 더 잘게 대조합니다. 기본값은 단어 단위입니다.
API 키나 해시, 토큰처럼 공백 없이 이어지는 문자열은 반드시 글자 단위로 보세요. 이런 값은 사실상 한 덩어리라 단어 단위로는 "통째로 바뀜"으로만 잡혀 어느 글자가 틀렸는지 안 보입니다. 글자 단위는 l과 1 한 자리 차이도 정확히 그 글자만 하이라이트합니다.
반대로 문장이나 코드처럼 공백으로 단어가 나뉘는 텍스트는 단어 단위가 편합니다. 변수명 하나, 단어 하나가 바뀐 걸 통째로 보여 줘서 눈이 덜 피로하죠. 글자 단위로 문장을 보면 스펠링 하나하나가 다 튀어 오히려 정신없습니다.
유사도 퍼센트는 어떻게 계산되나
우측 상단 유사도는 두 텍스트가 얼마나 겹치는지를 대략 보여 주는 지표입니다. 현재 선택한 비교 단위 기준으로, 양쪽에 공통으로 남은 부분이 전체에서 차지하는 비율을 계산합니다. 그래서 같은 두 텍스트라도 단어 단위일 때와 글자 단위일 때 값이 조금 달라질 수 있습니다.
두 값이 완전히 같으면 100%로 뜹니다. 키를 옮겨 적었다면 여기서 100%가 나와야 정상이고, 99.9% 같은 애매한 숫자가 보이면 어딘가 딱 한 글자가 어긋났다는 뜻입니다. 그럴 땐 글자 단위로 바꿔 하이라이트된 지점을 찾으면 됩니다.
어떤 방식으로 차이를 찾나
내부적으로는 jsdiff 라이브러리의 Myers diff 알고리즘을 씁니다. 두 텍스트를 늘어놓고 한쪽을 다른 쪽으로 바꾸는 데 필요한 삽입과 삭제의 수를 최소로 만드는 경로를 찾는 방식입니다. 최장 공통 부분수열(LCS) 개념과 맞닿아 있어서, 두 텍스트에 공통으로 살아남는 가장 긴 부분을 기준 삼아 나머지를 "추가"와 "삭제"로 갈라냅니다.
그래서 중간에 한 줄이 통째로 끼어들어도 뒤엣것이 전부 밀려 "다 바뀜"으로 뜨지 않고, 끼어든 줄만 초록으로 표시되고 아래는 그대로 정렬됩니다. 단순히 같은 자리끼리 짝지어 비교했다면 한 줄 삽입에 아래 전체가 어긋나 버렸겠죠.