URL 인코더
검색 결과 주소를 복사해 붙여넣었더니 한글이 %EB%B6%80%EB%8F%99%EC%82%B0 같은 알 수 없는 문자열로 바뀌어 본 적 있으실 겁니다. URL 인코더는 이렇게 URL에 그대로 담을 수 없는 한글·공백·특수문자를 퍼센트 인코딩(%XX) 형태로 바꿔 주고, 반대로 인코딩된 주소를 원래 텍스트로 되돌려 주는 도구입니다.
서버 로그를 들여다볼 때마다 q=%EA%B0%95%EB%82%A8 같은 문자열이 무슨 검색어였는지 매번 따로 변환해 보는 게 번거로웠습니다. API 요청을 테스트할 때도 한글 파라미터를 손으로 인코딩하다 자주 틀렸고요. 그 왕복이 싫어서, 붙여넣으면 바로 변환되는 걸 그냥 제가 쓰려고 만들었습니다.
사용 방법
지원하는 형식
인코딩에는 한글·공백·특수문자가 섞인 주소든 일반 텍스트든 무엇이나 넣을 수 있고, 결과로 퍼센트 인코딩된 문자열이 나옵니다. 디코딩은 반대로 %XX가 섞인 문자열을 넣으면 원래 텍스트로 복원해 줍니다.
-
위쪽에서 인코드·디코드 모드를 고릅니다. 한글을 주소에 안전하게 담을 때는 인코드, 암호처럼 보이는 문자열을 읽고 싶을 때는 디코드입니다.

-
왼쪽 입력창에 변환할 주소나 텍스트를 붙여넣습니다. 뭘 넣어야 할지 막막하면 샘플 버튼을 눌러 예시로 시작해도 됩니다.
-
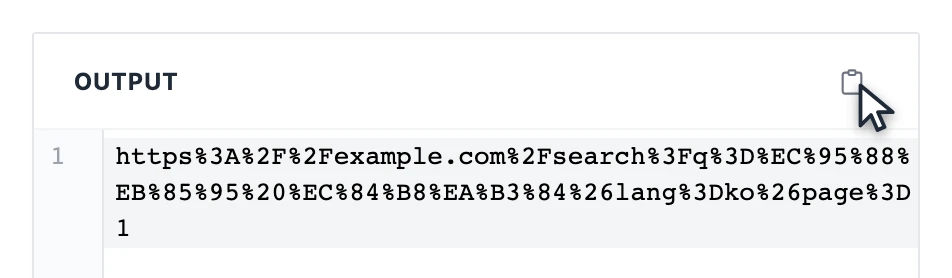
입력하는 즉시 오른쪽에 변환 결과가 나옵니다. 복사 버튼을 눌러 원하는 곳에 바로 붙여넣으세요.
URL에 한글·공백을 넣으면 왜 깨질까
URL은 처음 설계될 때부터 영어 알파벳·숫자와 일부 기호(ASCII)만 안전하게 실어 나르도록 만들어졌습니다. 그래서 한글이나 공백, 이모지처럼 그 범위를 벗어난 문자는 전송 도중 깨지거나 사라질 수 있죠. 이걸 막으려고 각 문자를 %와 16진수 조합으로 바꿔 보내는 방식이 퍼센트 인코딩입니다. 한글 한 글자가 %EC%95%88처럼 세 덩어리로 늘어나는 것도 이 때문입니다.
인코딩된 URL을 원래대로 되돌리기
디코드 모드로 바꾸면 같은 자리에서 반대로 동작합니다. 서버 로그에 찍힌 %EA%B0%95%EB%82%A8 같은 문자열을 붙여넣으면 '강남'처럼 원래 검색어로 풀어 주죠. 어디서 문제가 터졌는지 로그만 봐서는 알기 어려울 때, 이렇게 한 번 복원해 보면 상황이 한눈에 들어옵니다.