CSV → JSON 변환기
거래처에서 받은 표를 코드에서 다루려다 보면 결국 벽에 부딪힙니다. 엑셀이나 CSV로 온 2차원 표는 사람이 보기엔 편하지만, 막상 코드에서 반복 처리하려면 [{ name: "...", price: ... }] 같은 객체 배열이 훨씬 손에 잡히죠. CSV → JSON 변환기는 이 표를 헤더를 키로 삼은 JSON 객체 배열로 한 번에 바꿔 주는 도구입니다.
한두 줄이면 손으로 쳐도 되지만, 수백 행짜리 상품 목록이나 회원 명단을 매번 손으로 옮기는 건 실수만 늘 뿐이었습니다. 따옴표 안에 든 쉼표 하나 잘못 세면 열이 통째로 밀리고요. 그 지겨운 왕복을 없애려고, 붙여넣으면 바로 JSON이 나오는 걸 만들었습니다.
사용 방법
-
왼쪽 입력창에 CSV를 붙여넣습니다. 첫 줄이 헤더로 자동 인식되어 각 열의 키가 됩니다. 파일이 있으면 드래그하거나 파일 선택으로 올려도 되고, 감이 안 오면 샘플 버튼으로 예시부터 시작하세요.
-
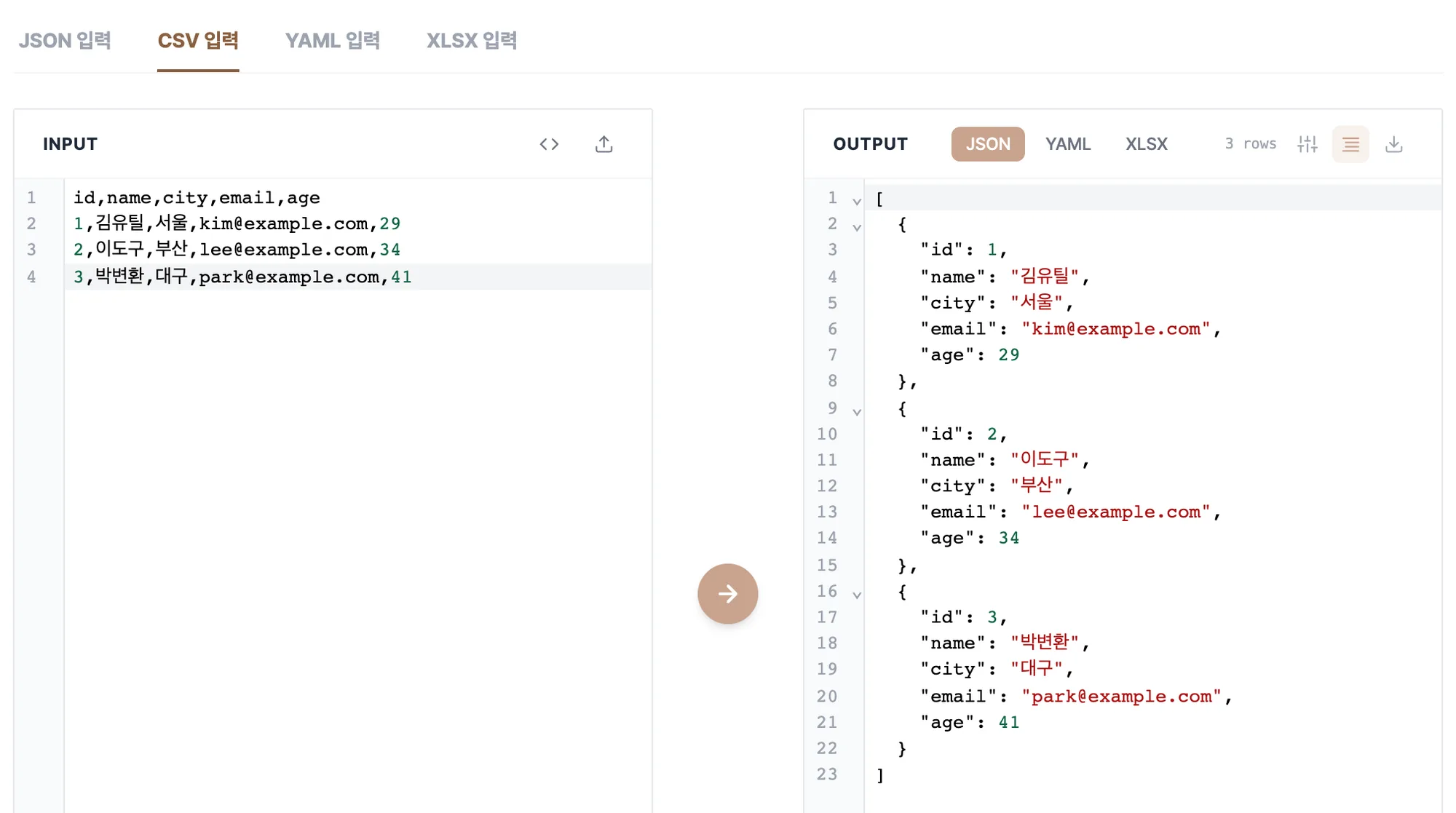
가운데 화살표를 누르면 JSON으로 변환됩니다. 입력을 멈추면 잠깐 뒤 자동으로도 변환되니, 값을 고치면서 결과가 어떻게 바뀌는지 바로 확인할 수 있습니다. 오른쪽 위에 행 수도 표시됩니다.
-
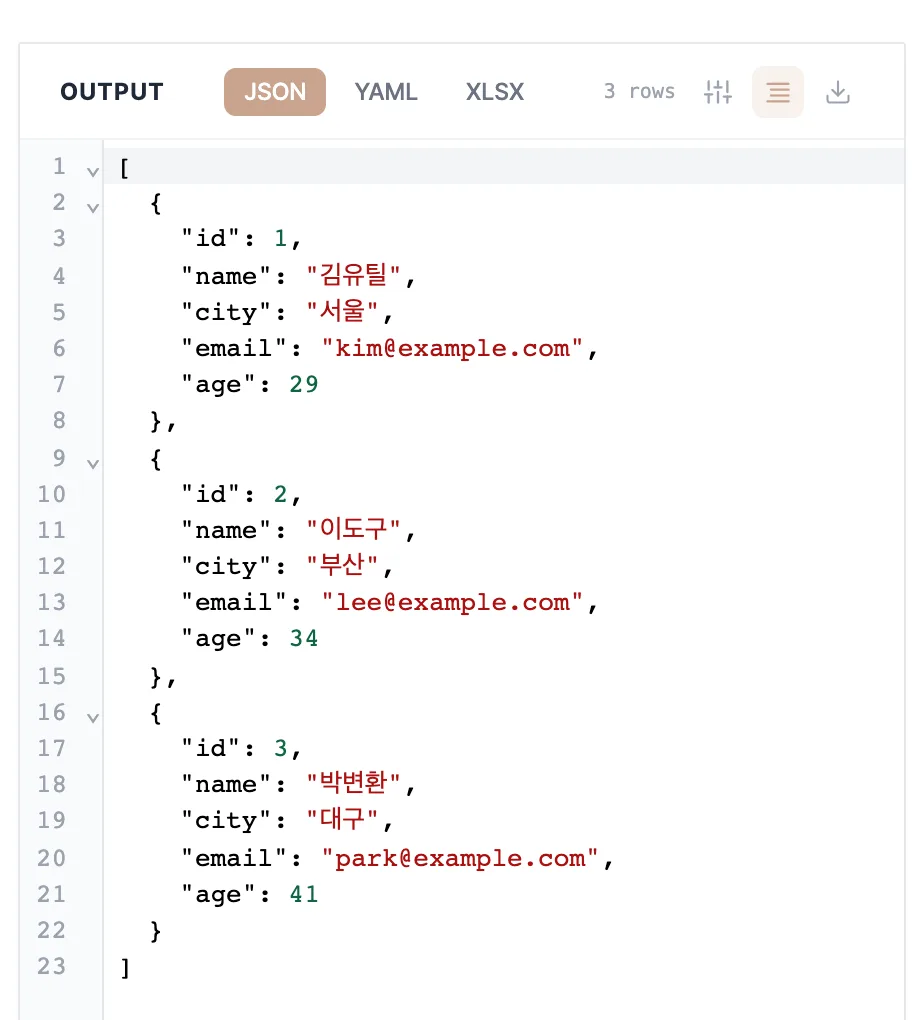
오른쪽에 나온 JSON을 복사해 코드에 그대로 붙여넣으세요. 파일로 내려받고 싶으면 다운로드 버튼을 쓰면 됩니다.
CSV와 JSON은 왜 근본적으로 다른가
CSV는 행과 열로만 이루어진 평평한 표입니다. 칸 하나에는 값 하나가 들어갈 뿐, 그 안에 또 다른 표를 품을 수 없죠. 반면 JSON은 객체 안에 객체, 배열 안에 객체를 얼마든지 겹쳐 담습니다. 이 차이가 두 형식을 오갈 때 대부분의 골칫거리를 만듭니다.
예를 들어 한 주문 안에 상품이 여러 개 들어 있는 구조를 CSV로 억지로 펴면 방법은 둘뿐입니다. 주문 정보를 상품 개수만큼 똑같이 반복해 여러 행으로 늘리거나, item1_name, item2_name처럼 열을 계속 늘리거나. 앞쪽은 데이터가 뻥튀기되고, 뒤쪽은 상품이 몇 개까지 올지 몰라 열이 폭발합니다. 계층이 깊은 데이터일수록 CSV는 점점 감당하기 어려워집니다.
그래서 보통 어떻게 쓰나
표준 방식은 단순합니다. 첫 행의 각 셀을 키로 쓰고, 나머지 각 행을 그 키에 값을 채운 객체 하나로 만들어 배열에 담습니다. 헤더가 name,email,age라면 각 행은 { "name": "...", "email": "...", "age": "..." }가 되는 식이죠.
중첩이 필요하면 헤더에 점 표기법을 씁니다. customer.name, customer.tier처럼 열 이름에 점을 넣으면 변환기가 이를 customer 객체 아래로 묶어 줍니다. 이 도구는 이 점 표기법을 그대로 이해해서, 평평한 CSV 열을 다시 계층 구조로 접어 JSON을 만듭니다. 오른쪽 Flatten 토글을 끄고 켜면서 펼친 상태와 접은 상태를 오가며 확인할 수도 있습니다.
한 가지 기억할 점은, CSV의 값은 본래 전부 문자열이라는 것입니다. age 열에 30이 들어 있어도 표에서는 숫자 30인지 문자열 "30"인지 구분이 없습니다. 변환된 JSON을 코드에서 받아 쓸 때 숫자나 불리언이 필요하다면, 그 형 변환은 받는 쪽에서 한 번 더 챙겨야 뒤늦은 버그를 피할 수 있습니다.