PDF 분할
계약서 60페이지짜리 PDF에서 상대방이 원한 건 서명란이 있는 3장뿐인데, 통째로 메일에 붙이자니 나머지 57페이지가 딸려 나가는 게 신경 쓰인 적 있으실 겁니다. PDF 분할은 이렇게 두꺼운 PDF에서 필요한 페이지만 골라 별도 파일로 떼어내는 도구입니다. 원본은 그대로 두고, 보내야 할 몇 장만 새 PDF로 뽑아냅니다.
세무서에 낼 서류 몇 장, 회의에서 보여줄 슬라이드 한 챕터. 매번 뷰어에서 인쇄 대화상자를 열어 "페이지 지정"으로 PDF 저장하는 게 번거로워서, 썸네일 보고 바로 골라 뽑을 수 있게 만들었습니다.
사용 방법
-
PDF 파일을 드래그하거나 클릭해서 올립니다. 잠시 뒤 모든 페이지가 썸네일 카드로 펼쳐집니다.
-
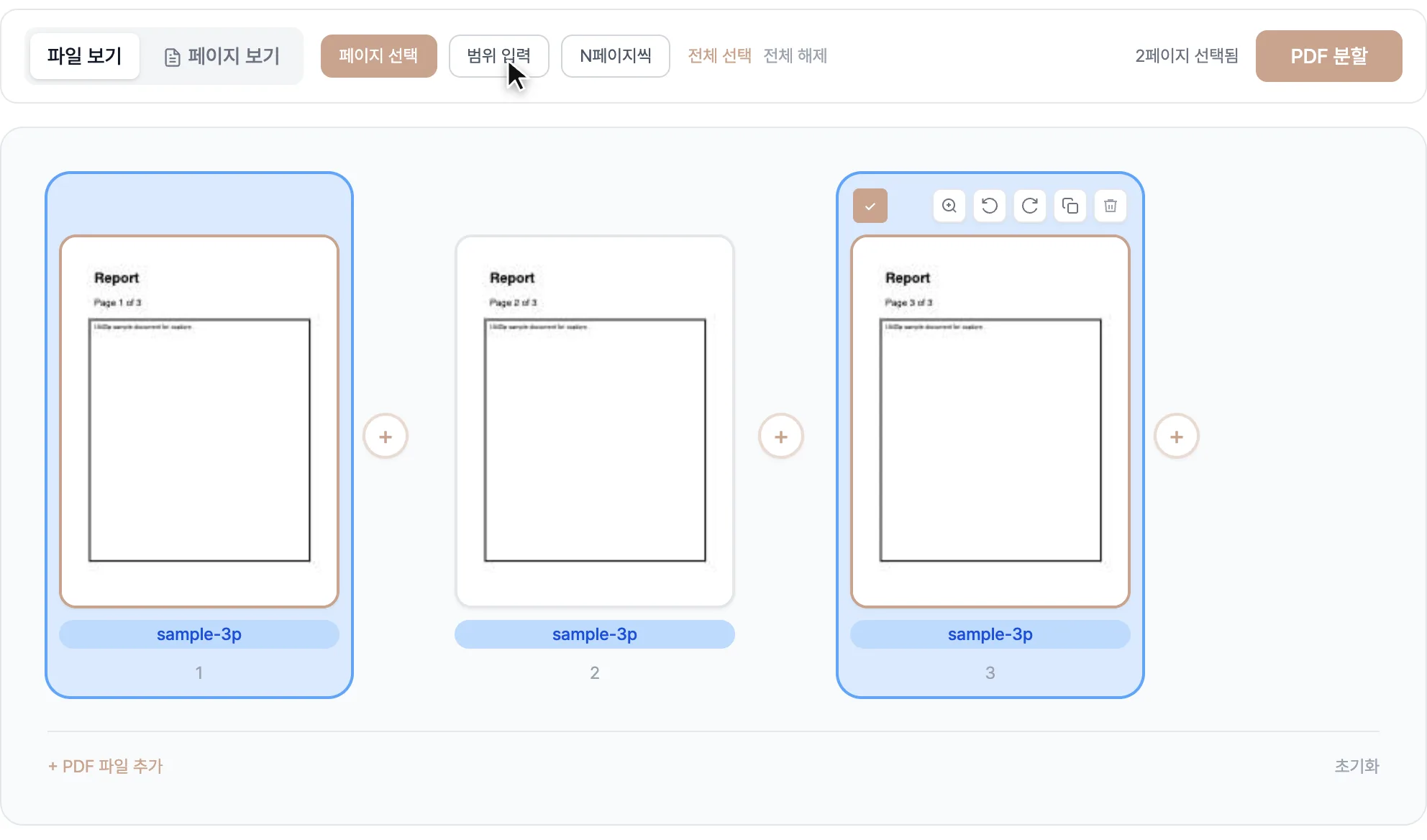
상단에서 분할 방식을 고릅니다. 페이지 선택은 카드를 눌러 원하는 장만 체크하고, 범위 입력은 1-3, 5, 7-9처럼 페이지 번호를 적고, N페이지씩은 예를 들어 10을 넣으면 10장 단위로 여러 파일로 쪼갭니다.
-
PDF 분할 버튼을 누르면 결과 파일이 만들어집니다. 옆에 뜬 ↓ split.pdf 버튼을 눌러 내려받으세요. N페이지씩 방식은 split_part1.pdf처럼 나뉜 파일이 각각 나옵니다.

두꺼운 PDF에서 몇 장만 빼내기
뽑을 페이지가 여기저기 흩어져 있으면 페이지 선택 모드가 편합니다. 썸네일을 눈으로 훑다가 필요한 카드만 클릭하면 파란 테두리로 표시되죠. 목차나 표지가 몇 페이지인지 정확히 기억나지 않아도 그림을 보고 고르면 되니 실수가 줄어듭니다.
반대로 "3장부터 7장까지, 그리고 10장" 하는 식으로 위치가 명확할 때는 범위 입력이 빠릅니다. 3-7, 10이라고 적으면 3·4·5·6·7·10번 페이지가 잡히고, 입력한 만큼 몇 페이지가 선택됐는지 바로 표시됩니다. 번호는 화면에 보이는 1번부터 세면 됩니다.
어느 방식이든 파일은 브라우저 안에서만 처리됩니다. 서버로 올라가지 않으니 계약서나 신분증 스캔본처럼 남에게 보이면 곤란한 문서도 그대로 넣어도 됩니다.
덩치 커서 안 열리는 PDF, 잘라서 열기
메일 첨부 용량 제한에 걸리거나, 열기만 해도 뷰어가 버벅대는 무거운 PDF가 있습니다. 이럴 때 N페이지씩 모드로 20장씩 끊어 두면 원본 하나가 감당 가능한 조각 여러 개로 나뉩니다. 필요한 구간의 조각만 열어 보거나 보내면 되니 전체를 통째로 다룰 일이 없어집니다.
다만 이 도구가 문서를 아무리 크게 잘라도 대신 삼켜 주지는 않습니다. 코드상 파일 크기나 페이지 수 상한은 따로 걸어두지 않았지만, 분할이 브라우저 메모리 안에서 이뤄지기 때문에 실질적인 한계는 열어 둔 브라우저 탭의 메모리입니다. 원본 PDF 전체를 메모리에 올린 뒤 페이지를 복사해 새 파일을 만드는 구조라서, 수백 메가 단위의 초대형 파일은 썸네일이 뜨는 데 시간이 걸리거나 탭이 무거워질 수 있습니다. 그런 파일일수록 오히려 이 도구로 먼저 잘게 쪼개 놓으면 다음부터 다루기가 한결 수월해집니다.